Why you should use edge functions with GraphQL
Learn why edge functions are perfect fit when using GraphQL

GraphQL is a great technology which provides a great DX and performance when used correctly. However, like every technology, it comes with several drawbacks. In this article, we will discuss those drawbacks and how we can solve them with edge functions (Cloudflare workers, Vercel edge runtime, etc) and a little bit of graphql-codegen.
Security
In my opinion, the most important concern when using GraphQL should be security. From my experience, most of the GraphQL servers, even behind an auth layer, are too exposed. Additionally, many articles about "How to secure a GraphQL server" are partially solving security vulnerabilities. The most common vulnerabilities are Denial of Service attacks (DoS) and Authentication & Authorization Vulnerabilities. This is mostly due to the ability of any client to traverse the GraphQL API in the way they want. When I test a GraphQL server for security, my first test is always a form sending custom queries to the server, and most servers just parse, validate and execute those queries.
An example:
query Dos {
user {
friends {
user {
friends {
user {
friends {
user {
friends {
## continue nesting...
}
}
}
}
}
}
}
}
}
For more in-depth information about security vulnerabilities (and solutions) check my previous article: https://ilijanl.hashnode.dev/why-and-how-to-secure-your-graphql-server
So how can we solve most of the vulnerabilities? The answer is whitelisting our queries/mutations. However, when having multiple clients sending different queries and mutations it becomes really hard to have a centralized whitelist. Fortunately, we can leverage edge functions as BFF (backend for frontend) gateway to hold a whitelist and accept and reject any incoming queries and mutations. Most of the applications (mobile or web) do have a compile/transpile step. We can extend this step to collect all queries and mutations and define a whitelist of queries/mutations on an application basis. Then we need to have a simple edge function handler which checks the incoming queries/mutations against the generated whitelist and proxies or blocks the requests to the origin GraphQL server:
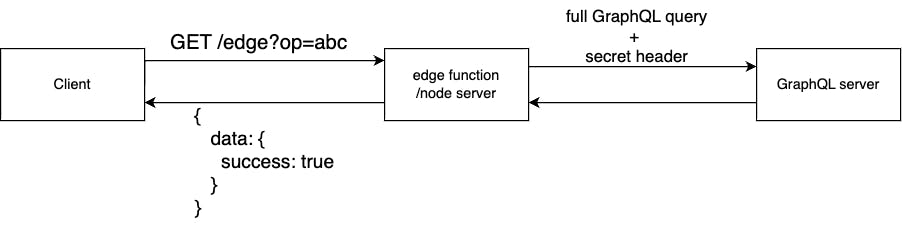
An example of an edge function handler (Cloudflare Worker):
import { createHandler } from '@graphql-edge/proxy';
import {
GeneratedOperation,
createOperationParseFn,
createOperationStore,
} from '@graphql-edge/proxy/lib/operations';
// this is generated by codegen, see @graphql-edge github examples for exact configuration
import OperationList from '../../__generated__/operations.json';
// store is used a whitelist store
const store = createOperationStore(OperationList as Array<GeneratedOperation>);
const parseFn = createOperationParseFn(store);
const handler = createHandler('https://countries.trevorblades.com', parseFn, {});
export default {
async fetch(request: Request, _env: unknown, ctx: ExecutionContext): Promise<Response> {
ctx.passThroughOnException();
const response = await handler(request);
return response;
},
};
I am using my own created package (https://github.com/ilijaNL/graphql-edge-proxy). Check the /examples for different use cases.
An additional benefit of using edge functions is that the request is terminated early if the incoming operation is not whitelisted, which results in low latency.
Using this setup still gives the same DX experience and improves security without introducing high costs (edge functions are cheap) and latency like other (GraphQL) gateways.
Analytics (+Versioning)
The advantage of edge functions is that they are running close to your end-users. You can leverage this feature to get more accurate analytics about the latency your users experience. In my opinion, these metrics are more useful than collecting the analytics on the origin server. With the help of these "more accurate" analytics, you can decide if you need more regions or more servers closer to your end users. Additionally, when collecting the right operation data, you can calculate your schema coverage. With this information, you can safely deprecate fields or introduce new fields without breaking any clients which are using your GraphQL server. A great tool and service to use is graphql-hive. GraphQL-Hive can be used to prevent breaking changes (CI/CD) and monitor the performance of your GraphQL API.
An example of an edge function handler (Cloudflare workers):
import { createUsageCollector, createHiveSendFn, UsageCollector } from 'graphql-hive-edge-client';
export interface Env {
HIVE_TOKEN: string;
}
let collector: UsageCollector | null = null;
export default {
async fetch(_request: Request, env: Env, ctx: ExecutionContext): Promise<Response> {
// singleton, we need the env.HIVE_TOKEN thus defining it inside fetch
if (!collector) {
const sendFn = createHiveSendFn(env.HIVE_TOKEN, {
clientName: 'cloudflare-worker-example',
});
collector = createUsageCollector({
send: (r) => {
console.info({ report: JSON.stringify(r, null, 2) });
return sendFn(r);
},
sampleRate: 1.0,
sendInterval: 2000,
});
}
// for test purposes use static definition, this definitions can be generated by codegen or be calculated runtime (worse performance)
const finish = collector.collect(
{
key: 'c844b925f03d2195287f817e0a67accb',
operationName: 'getProjects',
operation: 'query getProjects($limit:Int!){projects(filter:{pagination:{limit:$limit}type:FEDERATION}){id}}',
fields: [
'Query.projects',
'Query.projects.filter',
'Project.id',
'Int',
'FilterInput.pagination',
'FilterInput.type',
'PaginationInput.limit',
'ProjectType.FEDERATION',
],
},
{
name: 'hive-example-worker',
version: '0.0.0',
}
);
// dummy fetch, this should be a fetch to some graphql server
await fetch('https://mygraphql.com/graphql');
ctx.waitUntil(finish({ ok: true }).catch((e) => console.error(e)));
return new Response('Collected!');
},
};
After we can set up a CI/CD pipeline which detects if any breaking changes are introduced (backed by analytics) as described here: https://the-guild.dev/graphql/hive/docs/integrations/ci-cd. A full working example (with Hasura) can be found in my starter repo.
Caching
One major feature which most of the edge functions providers provide is the ability to cache at the edge. Traditionally GraphQL requests are sent as POST requests which are not cachable by default. Fortunately, because we are using edge functions, we can modify the frontend clients to send GET requests and convert those requests to POST requests in the edge function. Additionally, we can reduce request size by only sending the operation name and variables when having a whitelist at the edge:
A simple fetch function on the front end could look like this:
export const proxyFetch = <TData, TVars>(
documentNode: TypedDocumentNode<TData, TVars>,
variables?: TVars,
headers?: HeadersInit,
) => {
const operationName = extractOperationName(documentNode);
if (!operationName) {
throw new Error('operationName not specified');
}
const operationType = getOperationAST(documentNode, operationName);
if (!operationType) {
throw new Error('unknown operationType');
}
if (operationType.operation === OperationTypeNode.QUERY) {
const params = new URLSearchParams({
op: operationName,
});
if (variables) {
params.set('v', JSON.stringify(variables));
}
return graphFetch<TData>('GET', undefined, headers, '/api/edge?' + params.toString());
}
// add support for mutation
throw new Error(operationType + ' not supported');
};
An edge function (Vercel):
import { createHandler } from '@graphql-edge/proxy';
import {
GeneratedOperation,
createOperationParseFn,
createOperationStore,
} from '@graphql-edge/proxy/lib/operations';
// this is generated by codegen, see @graphql-edge github examples for exact configuration
import OperationList from '../../__generated__/operations.json';
// store is used a whitelist store
const store = createOperationStore(OperationList as Array<GeneratedOperation>);
const parseFn = createOperationParseFn(store);
const handler = createHandler('https://countries.trevorblades.com', parseFn, {});
export default async function MyEdgeFunction(request: NextRequest, event: NextFetchEvent) {
event.passThroughOnException();
const response = await handle(request);
// in seconds
const cacheTTL = 60;
// setting this header will cache the result at the edge
// this is a simple example and should be more specific (per operation basis etc)
response.headers.set('Cache-Control', `public, s-maxage=${cacheTTL}, stale-while-revalidate=${cacheTTL}`);
return response;
}
Conclusion
Using edge functions as a BFF for your GraphQL server gives many benefits such as edge analytics, edge caching and improved security without introducing high costs or high amount of latency. Additional features such as authentication or even authorization can be added.
I hope I convinced you why edge functions are a great fit when having a GraphQL server. Additionally, I made a starter repo which includes Hasura, NextJS, edge caching, edge analytics and codegen setup to get started with the discussed features: https://github.com/ilijaNL/ts-graphql-starter
Thanks for reading!


